
Early in my career, I stumbled upon this regular expressions cheat sheet by Dave Child in one of those “10 cheat sheets every developer should have”-type round-up articles.
I didn’t know much about regular expressions (also known as “RegEx” or simply “regex”) at the time, but it seemed like useful information to retain. I downloaded the PDF and stashed it away in a “resources” folder on my machine.
As my comfort with regex grew, I found myself referring back to the cheat sheet more and more often. I printed off a copy and taped it to the frame of the dry-erase board over my desk at the office. When I changed jobs, I printed a fresh-copy to decorate my otherwise pretty-bare cubicle walls.
I had been using regular expressions for several years before I first noticed that other developers were struggling. Patterns that seemed natural to me were complex ciphers to my peers, and an audible groan would echo through the office whenever a solution that leveraged regular expressions was proposed.
Here’s the rub: regular expressions don’t have to be that hard. They certainly require a bit of getting used to and some practice, but regex patterns are tremendously useful when validating data, searching files, or even filtering tweets.
Regular expressions are just patterns
The term “regular expression” can be a bit unnerving; what’s so regular about them? Why do they have to be so complicated? Let me reassure you: regular expressions are just patterns.
Prior to encountering regular expressions, most developers will be familiar with the common asterisk (“*”) wildcard character, as in:
|
1 |
$ git add src/*.js |
This is a common convention, where the asterisk represents anything. If the aforementioned src/ directory had four JavaScript files and a hundred CSS files, only the four files ending in “.js” would be staged within Git.
If databases are more your speed, you might have used the percent (“%”) operator in a SQL “LIKE” statement:
|
1 2 |
SELECT * FROM users WHERE email LIKE "%@aol.com" |
That statement will find any users with aol.com email addresses — the “%” works as a wildcard character.
Regular expressions build upon wildcards, but give us the ability to get more specific than just “match anything.”
For example, if we wanted to match AOL email addresses with “69” (nice) in them:
|
1 |
/69@aol.com/ |
A few things to note here:
- We’re wrapping the expression in forward slash (“/”) characters here: this is known as a “delimiter” character in regular expressions, and they could be almost any character as long as they match.
- We can add additional modifiers after the closing delimiter for things like case-insensitivity, which we’ll look at shortly.
- We don’t need to specify a wildcard character, since the regular expression is assuming that everything matches until it doesn’t. Read this as “match things that contain ’[email protected]'”.
- Matching email addresses with regular expressions is difficult, as the RFC that defines internet messaging addressing goes well-beyond “[email protected]”.
Anchors
Building on our previous example, imagine we have a number of email addresses that use subdomains, like “[email protected]”. Technically, this is a valid email address, but it’s not really an AOL address.
We can handle this case by using anchors — markers to specify the beginning or end of a line and/or set of data. The most common anchors are the caret (“^”) for the beginning of a string and the dollar sign (“$”) for the end of a string.
To filter out the sub-domain email address above, we can use the dollar sign:
|
1 |
/69@aol.com$/ |
This essentially says “find anything that ends in ’[email protected]'”.
Limiting the scope of our matches
At this point, we’re matching anything that ends in “[email protected]”, but our pattern may still capture more than we hoped. For example, imagine that Alice graduated from MIT in 1969 and, when she signed up for her email address, she selected “[email protected]”.
If our goal is finding users trying to be funny by appending “69” to their usernames, we might not want to catch Alice with our pattern. In this case, we might use character classes to limit our matches.
There are four character classes that you’ll commonly see in regular expressions:
- “\d” matches a digit character (e.g. 0-9)
- “\D” matches a non-digit character (e.g. anything except 0-9)
- “\s” matches a whitespace character (e.g. spaces, tabs, etc.)
- “\S” matches a non-whitespace character (e.g. digits, letters, etc.)
There are a number of other character classes available, but these are some of the ones I use and see most commonly.
You’ll notice that in those four, the lowercase form is the affirmative (e.g. “yes, I want digits”) whereas the uppercase form is the negative (“no, I don’t want any digits”). If it helps to remember this, I remember Dean Vernon from the Mars University episode of Futurama:

The fact that he’s so upset over Robot House’s wacky antics makes him shout “Robot House!” Meanwhile, those who were pro-Robot House were much more likely to say the robot fraternity’s name without raising their voices.
Anyway, back to Alice: if we decide we don’t want to match an address ending in “[email protected]” that’s preceded by more digits (e.g. “1969”), we might use the non-digit character class:
|
1 |
/\D69@aol.com$/ |
This tells the regular expression engine that we’re looking for strings that end in a non-digit character, followed by “[email protected]”. As a result, Alice would be excluded from the matches.
Escaping special characters
As we get into more complex regular expressions, you’ll undoubtedly find situations where you need to escape special meta-characters (the characters used by regular expressions themselves). In the example we’ve been building up to this point, we’ve [intentionally] left one meta-character un-escaped: the period (“.”).
Within regular expressions, the period (or “dot”) matches any character except a newline/line-break. As a result, the following string would technically match our current regular expression pattern: “summerof69@aolfcom”.
Now, I don’t know if “aolfcom” is a real brand name, but it’s used here to demonstrate a point: since the dot matches any character, this would fit our pattern. Instead, we want to escape the dot using a backslash (“\”) character:
|
1 |
/\D69@aol\.com$/ |
Now, only non-digits followed by “69@aol.com” at the end of the string will be matched.
Matching multiple patterns
This is where regular expressions get really exciting: the ability to match multiple patterns at the same time.
Let’s take our little email address search one step further — we want to find any email address ending in “[email protected]” or “[email protected]”. We can do this using the pipe (“|”) operator:
|
1 |
/\D(69|420)@aol\.com$/ |
This pattern would match any address that ends in either “[email protected]” or “[email protected]”, with that ending immediately preceded by a non-digit character.
Note that this is technically creating a capturing group, which we’ll discuss later. This may also be written as the following to use a non-capturing group:
|
1 |
/\D(?:69|420)@aol\.com$/ |
Using quantifiers
Another powerful and common use-case for regular expressions is matching sequences using quantifiers. Put into practical terms: “some jokers are going to put ’69’ at the end of their addresses a few times.”
We can detect this using various quantifiers:
- * matches 0 or more instances.
- ? matches exactly 0 or 1 instances.
- + matches 1 or more instances.
- {2} matches exactly 2 instances
- {2,4} matches 2, 3, or 4 instances.
- {4,} matches 4 or more instances
The most common quantifiers are typically the first three: “*”, “?”, and “+”.
For example, if we want to catch email addresses like “[email protected]” and “[email protected]”, we could expand our regular expression:
|
1 |
/\D(69|420)+@aol\.com$/ |
This tells the regex engine “find strings that have a non-digit character, followed by one or more instances of ’69’ and/or ‘420’, then ends in ‘@aol.com’.”
Matching ranges using regular expressions
We don’t always know what characters we’re looking for, and regex has operators to help with that. We can use regular expressions to declare a set of characters we want to look for, then drop them into our expression.
I graduated high school at the peak of the “emo” music trend, so I had a lot of friends who would have screen names or email addresses like “[email protected]” (the early 2000s were a weird time).
If we wanted to capture these, we could create a range of characters and put them at the start of the pattern:
|
1 |
/^[xX_]{2,}.+\D(69|420)+@aol\.com$/ |
This pattern matches any string that begins with two or more characters from the set of “x”, “X”, and “_”, has one or more of any character, followed by a non-digit character, then one or more instances of “69” and/or “420”, finishing in “@aol.com”.
You’ll notice this example also introduces the caret (“^”) anchor, which signifies the beginning of the string. If the email begins with any character besides “x”, “X”, or “_”, the email address will not be matched.
Using pattern modifiers
If you recall, our regular expressions both begin and end with delimiters. Why? That tells the regex engine where to begin and end parsing a pattern, but also gives us the opportunity to use modifiers to change the way the engine behaves.
For example, regular expressions are typically case-sensitive by default. Email addresses, however, are not — some people will provide their email addresses in mixed-case or all-caps. Our current pattern would not catch an email address like “[email protected]”, since we’re looking for emails ending in “@aol.com” (all lowercase).
We can get around this using the “i” modifier (short for “case insensitive”) to signal to the regex engine that we don’t want to worry about case sensitivity. Since we’re ignoring that, we can also safely drop one of the “X” characters from our angsty, emo range:
|
1 |
/^[x_]{2,}.+\D(69|420)+@aol\.com$/i |
Hopefully this shows how you can go about building out a regular expression, from simple wildcards to complex patterns. There’s a lot more that can be done (like assertions, which are awesome but can make your head hurt), but these features cover a lot of the most common uses for regular expressions I’ve seen in the wild.
Using regular expressions for find + replace
A great, common use-case for regular expressions is replacing sections of text. For example, let’s consider this simple passage:
When I was younger, we’d eat McDonald’s all the time. Lunch, dinner, even breakfast if we were on the road to my grandparents’ house. It wasn’t until I got older that I learned McDonald’s isn’t very good for me, and there are no redeeming qualities in McDonaldLand cookies.
Now, let’s imagine that the McDonald’s corporate office sees that and issues an immediate cease-and-desist. I still want to share that information with the world, however, so I might get clever and want to replace any references to “McDonald’s” with “McArches”.
A simple find + replace for “McDonald’s” would catch the first two instances, but McDonaldLand would still be left. Instead, I might use PHP’s preg_replace() function:
|
1 |
$content = preg_replace('/McDonald\S+/i', 'McArches', $content); |
This will find any word that begins in “McDonald” and ends in at least one non-whitespace character and, if found, will replace it with “McArches”. That means the pattern will catch “McDonald’s”, “McDonaldLand”, and “McDonald’sPleaseDon’tSueMe”.
Using capture groups
Sometimes, we find ourselves needing to parse out a selection of data so we can reformat it. This is where the matching groups I mentioned before come into play.
By wrapping a segment of the regular expression in parentheses, the portion that matches will be available to us in subsequent operations.
For example, let’s grab some popular research into animal sounds, which tells us:
Dog goes “woof”
Cat goes “meow”
Bird goes “tweet”
And mouse goes “squeek”
Cow goes “moo”
Frog goes “croak”
And the elephant goes “toot”
Ducks say “quack”
And fish go “blub”
And the seal goes “ow ow ow”
Imagine we’re tasked with extracting not only the animals, but their corresponding sounds from this list. Fortunately, the format is fairly consistent, with the pattern of “animal verb sound-in-quotes”.
The verb in question is one of “goes”, “go”, or “say”, and a few lines have modifiers at the beginning — either “and” or “and the”.
A basic regular expression to match this pattern might look like:
|
1 |
/([A-Z]+)\s(?:go|goes|say)\s"(.+)"/gi |
This will find some string of alphabetical characters (e.g. the animal name, capture group 1), followed by one whitespace character, one of “go”, “goes”, or “say”, another whitespace, then a second capture group surrounded by quotation marks.
Each capture group would then be available to us, typically in the form of $n (where “n” is the number of the capture group, starting at 1).
If we use a function like PHP’s preg_match(), we can get an array of matches for each capture group, then put together a simple animal:sound pairing.
We could also take advantage of the preg_replace() function from earlier to make the song significantly less-catchy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$regex = '/([A-Z]+)\s(?:go|goes|say)\s"(.+)"/i'; $lyrics = 'Dog goes "woof" Cat goes "meow" Bird goes "tweet" And mouse goes "squeek" Cow goes "moo" Frog goes "croak" And the elephant goes "toot" Ducks say "quack" And fish go "blub" And the seal goes "ow ow ow"'; echo preg_replace($regex, '$1 makes a "$2" sound.', $lyrics); |
The result? Check out 2019’s hit new remix!:
Dog makes a “woof” sound.
Cat makes a “meow” sound.
Bird makes a “tweet” sound.
And mouse makes a “squeek” sound.
Cow makes a “moo” sound.
Frog makes a “croak” sound.
And the elephant makes a “toot” sound.
Ducks makes a “quack” sound.
And fish makes a “blub” sound.
And the seal makes a “ow ow ow” sound.
It really makes you want to move your feet [away from the speaker], doesn’t it?

Testing regular expressions
When writing more complex regular expressions, I’ve found tools like RegExr to be a tremendous asset. Beyond being an excellent resource for debugging regular expressions, RegExr also provides live highlighting of matches within example content.
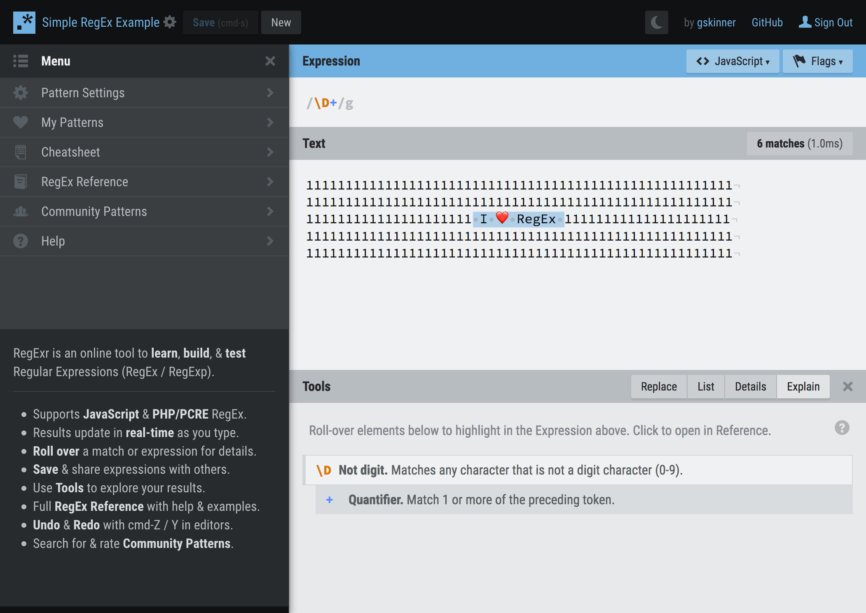
All of those email address examples earlier in the article? Try them for yourself!
If I’m working on a particularly-complicated pattern, I’ll often put a sample of the data into RegExr and work out the pattern there before copying it into my application.
Leveling up your regular expressions game
Once you have a grasp on how regular expressions work, you might hit the links of Regex Golf.
Like actual golf, Regex Golf is all about trying to get the lowest score possible. The more characters you use in your pattern, the higher your score. The game doesn’t do a great job of teaching you regular expressions, but it does help you reduce the complexity of your RegEx patterns.
Like any golf-style coding game, please remember: it’s more important to have readable code than a jumble of super-optimized regular expressions that nobody is able to understand. If you’re working on a team or in open source, please add a comment for any non-trivial regular expression!
Conclusion
Hopefully this has helped demystify the most common regular expressions and show that they don’t have to be scary. Like any other sort of tool there’s some degree of learning curve, but getting even a basic grasp on regex can be a huge addition to your toolbox.
Are there tips, tricks, and/or tools that have helped you? Please leave them in the comments!


Leave a Reply